scrapy抓取免費代理IP
- 来源:未知 原创
- 时间:2018-08-05
- 阅读: 次
- 本文标签:
1、創建項目
scrapy startproject getProxy
2、創建spider文件,抓取www.proxy360.cn www.xicidaili.com兩個代理網站內容
cd項目的spiders模塊下執行
scrapy genspider proxy360Spider proxy360.cn
scrapy genspider xiciSpider xicidaili.com
scrapy shell http://www.proxy360.cn/Region/China
scrapy shell http://www.xicidaili.com/nn/2
執行結果發現proxy360.cn response 返回200,西刺網返回500需要修改一下默認的請求頭參數
3、項目文件結構

4、需要修改settings文件的user agent通過瀏覽器代理抓取
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36(KHTML, like Gecko)'
5、打開items文件,定義需要爬取的字段
scrapy
(scrapy.Item):
ip = scrapy.Field()
port = scrapy.Field()
type = scrapy.Field()
location = scrapy.Field()
protocol = scrapy.Field()
source = scrapy.Field()
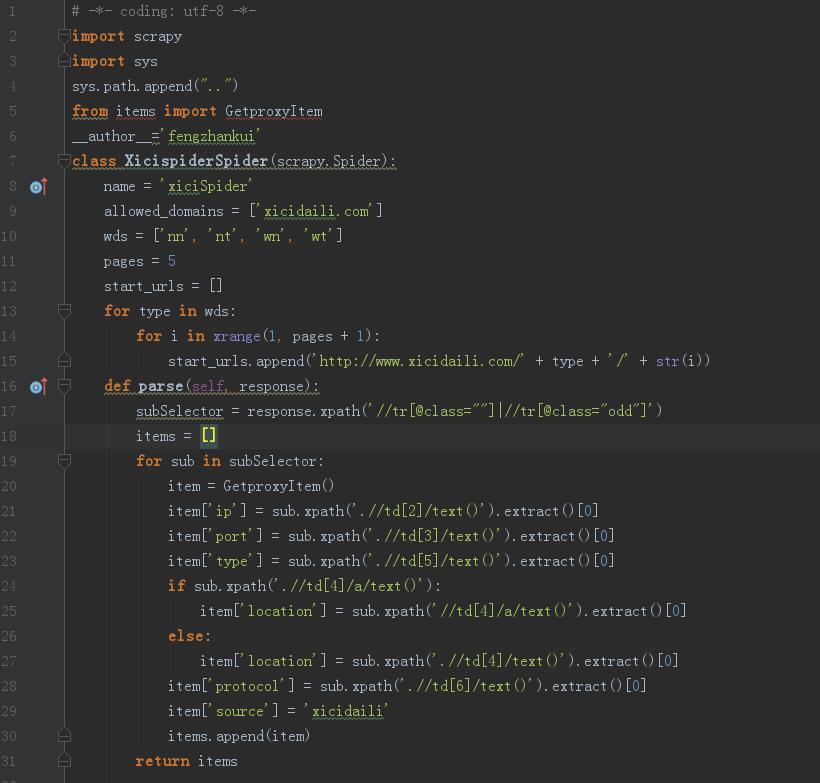
6、打開proxy360Spider定義爬取的邏輯

打開xiciSpider定義西刺網爬取的邏輯
scrapy
sys
sys.path.append()
items GetproxyItem
__author__=(scrapy.Spider):
name = allowed_domains = []
wds = []
pages = start_urls = []
type wds:
i (pages + ):
start_urls.append(+ type + + (i))
(response):
subSelector = response.xpath()
items = []
sub subSelector:
item = GetproxyItem()
item[] = sub.xpath().extract()[]
item[] = sub.xpath().extract()[]
item[] = sub.xpath().extract()[]
sub.xpath():
item[] = sub.xpath().extract()[]
:
item[] = sub.xpath().extract()[]
item[] = sub.xpath().extract()[]
item[] = items.append(item)
items
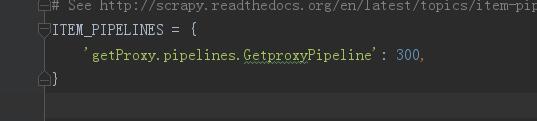
7、定義爬取結果,數據處理層pipelines
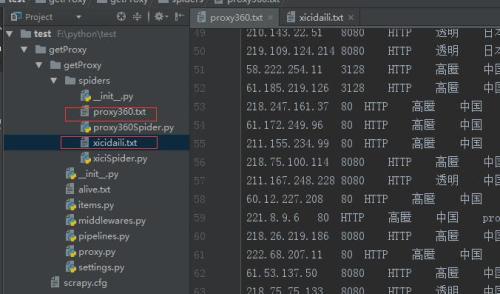
分別將proxy360網站的數據存到prox360.txt文件
西刺網的爬取數據存到xicidaili.txt文件
8、打開settings裏面關於pipelines的定義
9、在spiders模塊下分別執行,生成抓取的文本內容
scrapy crawl proxy360Spider
scrapy crawl proxy360Spider
10、爬取结果到此结束,但是并不是每一个代理都是可用的,所以需要我们再去验证一下,过滤出来可用的代理,getProxy模块下创建proxy文件获取可用代理
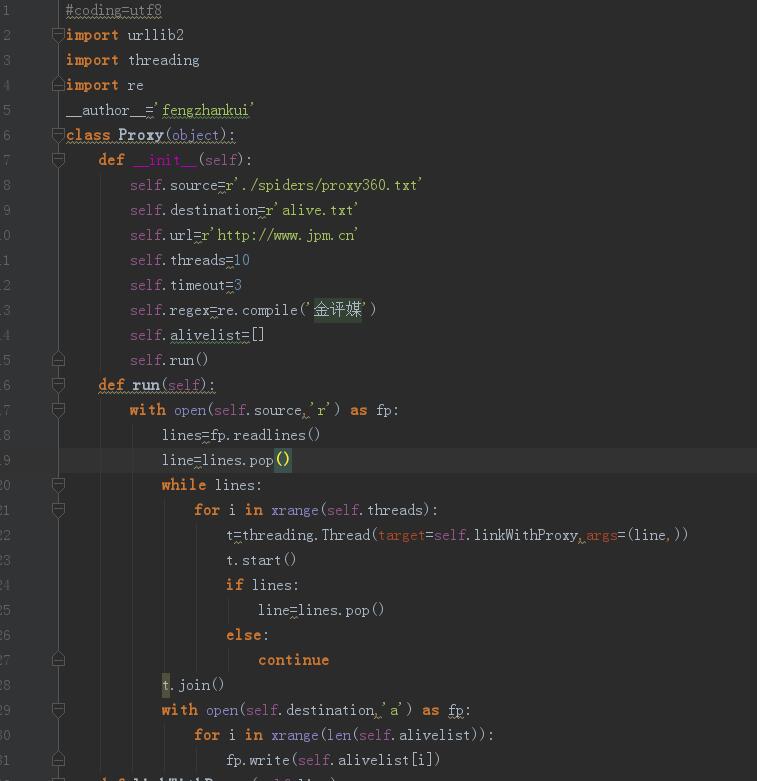
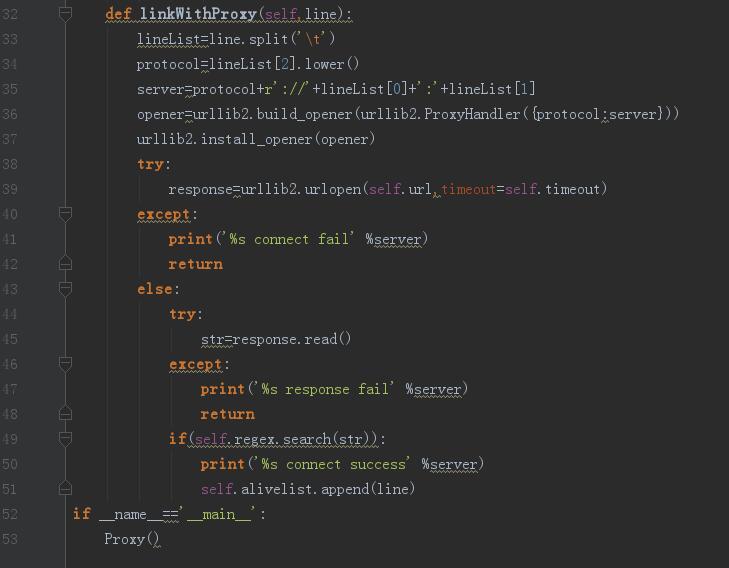
11、最後得到alive.txt文件存放可用的代理結果,至此結束
相关文章
本文链接:http://www.it892.com/content/ip/2018/0805/108073.html